

How to automatically read data from invoices using Rossum API: an example with Google Drive
![]()
Please note that this example is not relevant anymore.
Our research programmer, Roman Sushkov, recently posted a neat example of how to use Rossum’s Data Extraction API in practice. We think it is a great introduction to practical usage of our API – we are re-posting it below.
Introduction
Note: This example uses a historic version of Rossum’s API that we do not recommend to use anymore.
In this tutorial, I will show how to automate invoice processing by integrating Google Drive and the Rossum API. We will need:
- Rossum developer account
- Google drive account
- Invoices in PNG, JPG, or PDF format
- Python interpreter
Create a Rossum developer account
First, you need to create your developer account. You will receive a unique secret key that you will need for API access upon registration. Rossum developer account is free with the quota of 300 invoices per month.
Configure your Google Drive
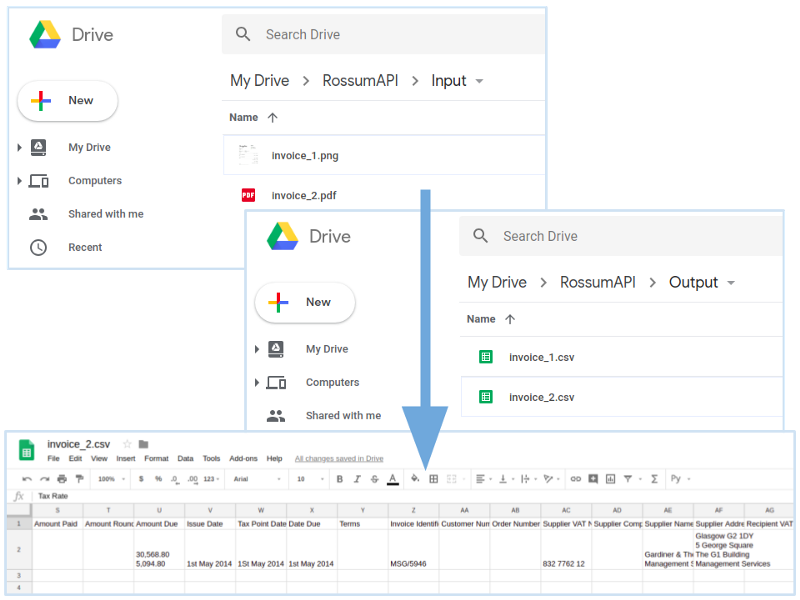
First, enable Google Drive API by following Step 1 in the Google Drive API documentation. Keep the credentials on file, we will need it in the next step! Second, upload the invoices to your Drive. In this tutorial, the following folder structure is assumed:
RossumAPI # Create RossumAPI folder in your Drive |--- Input # Copy the invoices to the Input folder | |--- inv_1.pdf | |--- invoice_a.pdf | |--- invoice_x.pdf | |--- ... | |--- invoice_N.png |--- Output # The results will be saved in the Output # folder
Process invoices
The script for using Rossum API are published in Rossum repository. Clone it to your computer and install the dependencies:
git clone https://github.com/rossumai/elis-client-examples.git cd elis-client-examples/google-drive-integration pip install rossum
Copy your google drive credentials (the file that you downloaded in the previous step) to the working directory and name it client_secret.json.
mv ~/Downloads/PATH_TO_CREDENTIALS client_secret.json
And finally, process the invoices using the following command (replace _YOUR_ROSSUM_SECRET_ with your secret key):
python parse_invoices.py --secret-key _YOUR_ROSSUM_SECRET_
This is it! In three easy steps, we processed the invoices and saved the results in Google Drive.
Now, let’s have a look at the code!
Code
Rossum API
You can use the Rossum engine using its API. It is minimalistic and has two modes: sending a document and reading the parsed results. The requests package is used for this purpose:
def send_document(self, document_path):
"""
Submits a document to Elis API for extractions.
Returns: dict with 'id' representing job id
"""
with open(document_path, 'rb') as f:
content_type = self._content_type(document_path)
response = requests.post(
self.url + '/document',
files={'file': (os.path.basename(document_path), f, content_type)},
headers=self.headers)
return json.loads(response.text)
Akin to uploading documents, we can check for the processing status (which is either ready or processing).
def get_document_status(self, document_id):
"""
Gets a single document status.
"""
response = requests.get(self.url + '/document/' + document_id, headers=self.headers)
response_json = json.loads(response.text)
if response_json['status'] != 'ready':
print(response_json)
return response_json
Since the documents are processed asynchronously, it is necessary to periodically check until they are processed.
def get_document(self, document_id, max_retries=30, sleep_secs=5):
"""
Waits for document via polling.
"""
def is_done(response_json):
return response_json['status'] != 'processing'
return polling.poll(
lambda: self.get_document_status(document_id),
check_success=is_done,
step=sleep_secs,
timeout=int(round(max_retries * sleep_secs)))
The documents may be submitted at the same time and processed in parallel. A simple way to leverage it is to use the Python futures library:
def parse_document(fname):
print('[Elis] Submitting document:', fname)
send_result = client.send_document(fname)
document_id = send_result['id']
print('[Elis] Document id:', document_id)
return client.get_document(document_id)
# `parse_document` is called in parallel
# and the results are saved in `dicts`
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
dicts = executor.map(parse_document, files)
Google Drive API
In order to start working with Google Drive API, the first thing that you need is an instance of googleapiclient.discovery.Resource (called service in the following snippet).
SCOPES = '<https://www.googleapis.com/auth/drive>'
store = file.Storage('credentials.json')
creds = store.get()
if not creds or creds.invalid:
flow = client.flow_from_clientsecrets('client_secret.json', SCOPES)
flags = tools.argparser.parse_args(args=[]) # ignore command line arguments
creds = tools.run_flow(flow, store, flags)
# build the Resource object
service = build('drive', 'v3', http=creds.authorize(Http()))
You can search the files using a special query syntax of the service.files.list() method, for example using the following queries:
# Find a Google Drive folder named RossumAPI
q = "name='RossumAPI' and mimeType='application/vnd.google-apps.folder'"
# Find all files in the given folder id
q = "'{}' in parents and trashed=false".format(folder_id)
You can list all files in a given folder and download them using these functions:
def find_files_in_folder(folder_id):
q = "'{}' in parents and trashed = false".format(folder_id)
page_token=None
response = service.files().list(q=q,
spaces='drive',
fields='nextPageToken, files(id, name)',
pageToken=page_token).execute()
files = response.get('files', [])
return files
def download_file(fid, name):
create_folder('invoices')
request = service.files().get_media(fileId=fid)
with io.FileIO(os.path.join('invoices', name), 'wb') as fh:
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
After processing the documents, the results are uploaded to cloud, ideally in the native Google Drive format. Since we want to upload CSV files, it is natural to save them as spreadsheets. Luckily, conversion is supported out of the box by specifying the file’s mimeType:
def upload_csv(folder, path):
fname = os.path.basename(path)
file_metadata = {
'name': fname,
'mimeType': 'application/vnd.google-apps.spreadsheet',
'parents': [folder.get('id')]
}
media = MediaFileUpload(path,
mimetype='text/csv',
resumable=True)
file = service.files().create(body=file_metadata,
media_body=media,
fields='id').execute()
The snippets of code were taken from Rossum examples repo, feel free to explore them to learn more!